November 27, 2024
Editors' notes
This article has been reviewed according to Science X's editorial process and policies. Editors have highlighted the following attributes while ensuring the content's credibility:
fact-checked
trusted source
proofread
Retrieve-Revise-Refine: A novel framework for retrieval of concise entailing legal articles
. DOI: 10.1016/j.ipm.2024.103949")
Artificial intelligence (AI) continues to redefine the boundaries of legal technology, offering to automate advanced tasks such as legal question answering and consultation. In the domain of statute law, a particular challenge is the task of retrieving the concise set of entailing legal articles to a query. In this context, we refer to this task as entailing legal article set retrieval or, more briefly, legal article set retrieval.
The task of retrieving entailing legal article sets differs markedly from traditional information retrieval (IR) in two main aspects. First, unlike the traditional IR which returns a ranked list of articles, the legal article set retrieval task seeks a concise set of articles. This level of specificity extends to the nature of the legal queries and legal articles themselves: They are inherently complex and steeped in specialized legal language, demanding a retrieval system with deeper legal reasoning and linking capacity.
Second, while traditional IR efforts primarily involve ranking candidates by relevance, our task requires that the retrieved articles not just relate to but jointly entail the contents of a query or its negation. These characteristics set this task apart from the broader goals and methods of traditional IR tasks.
Previous research in legal article set retrieval has predominantly employed two approaches. The first approach combines classical IR models with fine-tuned language models (LMs), and then ensembles the retrieval results to consolidate the final retrieved sets. Meanwhile, the second approach uses classical IR models exclusively for preliminary candidate filtering, which prepares inputs for further LM fine-tuning; the final results are often ensembled from various fine-tuned LMs.
To address the task of legal article retrieval, a team of researchers from the Japan Advanced Institute of Science and Technology (JAIST), led by Professor Le-Minh Nguyen and including doctoral students Chau Nguyen proposed a framework, called Retrieve-Revise-Refine. The framework is designed to pinpoint the concise set of legal articles that either entail a query or its negation, advancing the current understanding of this task.
In addition, their approach leverages the unique advantages of combining both small LMs and large LMs to improve the accuracy of the articles retrieved (i.e., precision), while endeavoring to limit the loss in coverage (i.e., recall). The paper is published in the journal Information Processing & Management.
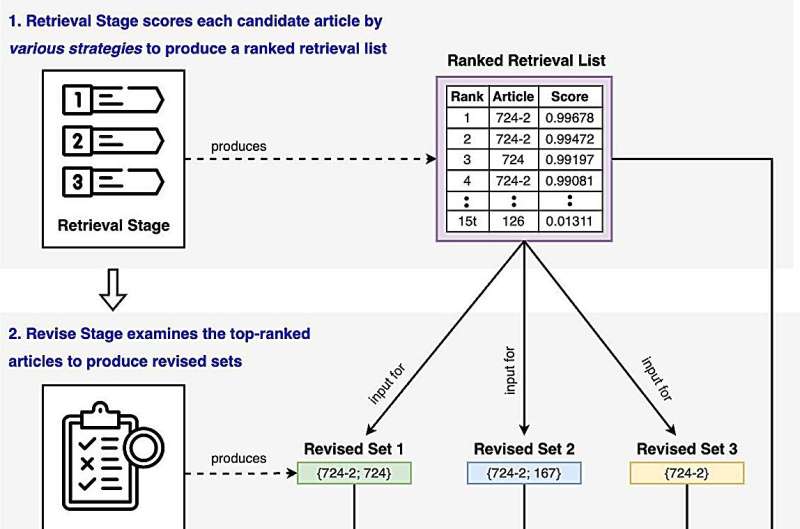
The framework consists of three stages:
- Retrieve: Maximizing the comprehensive retrieval of entailing articles using an ensemble of multiple small LMs, fine-tuned with various tailored strategies.
- Revise: Large LMs are utilized to assess the validity of the query with respect to each combination of articles from the top retrieval results, aiming to derive a more compact subset of entailing legal articles.
- Refine: Further distilling the outputs from the second stage, using insights derived from the small LMs' predictions as refiners for the predictions of the large LMs.
As shown in the empirical results, their proposed framework achieved state-of-the-art results for the task across two datasets, showing improvements of 3.17% and 4.24%, respectively.
More information: Chau Nguyen et al, Retrieve–Revise–Refine: A novel framework for retrieval of concise entailing legal article set, Information Processing & Management (2024). DOI: 10.1016/j.ipm.2024.103949
Provided by Japan Advanced Institute of Science and Technology Citation: Retrieve-Revise-Refine: A novel framework for retrieval of concise entailing legal articles (2024, November 27) retrieved 27 November 2024 from https://techxplore.com/news/2024-11-refine-framework-concise-entailing-legal.html This document is subject to copyright. Apart from any fair dealing for the purpose of private study or research, no part may be reproduced without the written permission. The content is provided for information purposes only.
Explore further
A multi-relational graph perspective on semantic similarity in program retrieval shares
Feedback to editors